StackOverflow already had a bad reputation. Genuine questions from developers, especially newcomers, were often met with ridicule or outright hostility from experienced individuals. The proud culture has been the source of countless memes.
Yet the broken system was working. A tiny percentage of the platform users would ask a question when completely stuck. Some of the questions were so far-off, obscure, and unpredictable that somebody someday had to ask them to clarify. They could not be anticipated and documented beforehand.
GitHub issues were serving as a knowledge base for open-source software. It was probably less hostile than StackOverflow, with long threads of back-and-forth comments, liked and disliked by the community. The help was real.
Reddit was a gold mine of information. It still is, though it has some characteristics of StackOverflow attitude. Add Quora to the list, but the one before the management ruined the platform and pushed all the great writers out.
And finally, so many technology blogs, personal and company. They were the biggest source of information outside the well-established platforms, and the incentive for writing was, among other things, monetization and SEO.
But what’s the current status of all these platforms? From what I have heard, Stackoverflow engagement has gone way down since the release of ChatGPT and other generative AI assistants. I have anecdotal evidence from friends and colleagues, that most Googling has been replaced by AI prompts. I don’t know about other blogs, but I did cut down on writing, lacking motivation. I assume others would have done the same or some of them may have started producing wholesale AI slop. Reddit should surely be going strong, but I doubt its subreddits have the required depth for technical discussions; they are more high-level opinion-based than exact programming issues. For challenging technical problems, the consumer is going for ease and accuracy, and the producer doesn’t have the incentive to continue.
What’s the point of asking a question on Stackoverflow when you have the answer at your fingertips at ChatGPT, Gemini, Deepseek, or code companions like Cursor or Copilot? And what’s the incentive of answering a Stackoverflow question, writing a blog post, or commenting on a GitHub issue (unless you’re a contributor), when you know that your work will be trained for free and will end up taking the traffic away from your work (ironically) based on your work? Add the reader to the mix too. How confident are you to read something from all these sources when the possibility of it being a useless AI slop is real? The knowledge ecosystem is in the process of breaking. That is true for all knowledge on the internet, but more so for software.
You may think that the working code produced by the developers will be of high quality, and therefore will be an endless source for training through millions of GitHub and Bitbucket repositories. You haven’t heard of vibe coding then. It’s a synonym of slop, specific to coding. It will only increase the signal-to-noise ratio exponentially, making it tough to filter out accurate and helpful information for training.
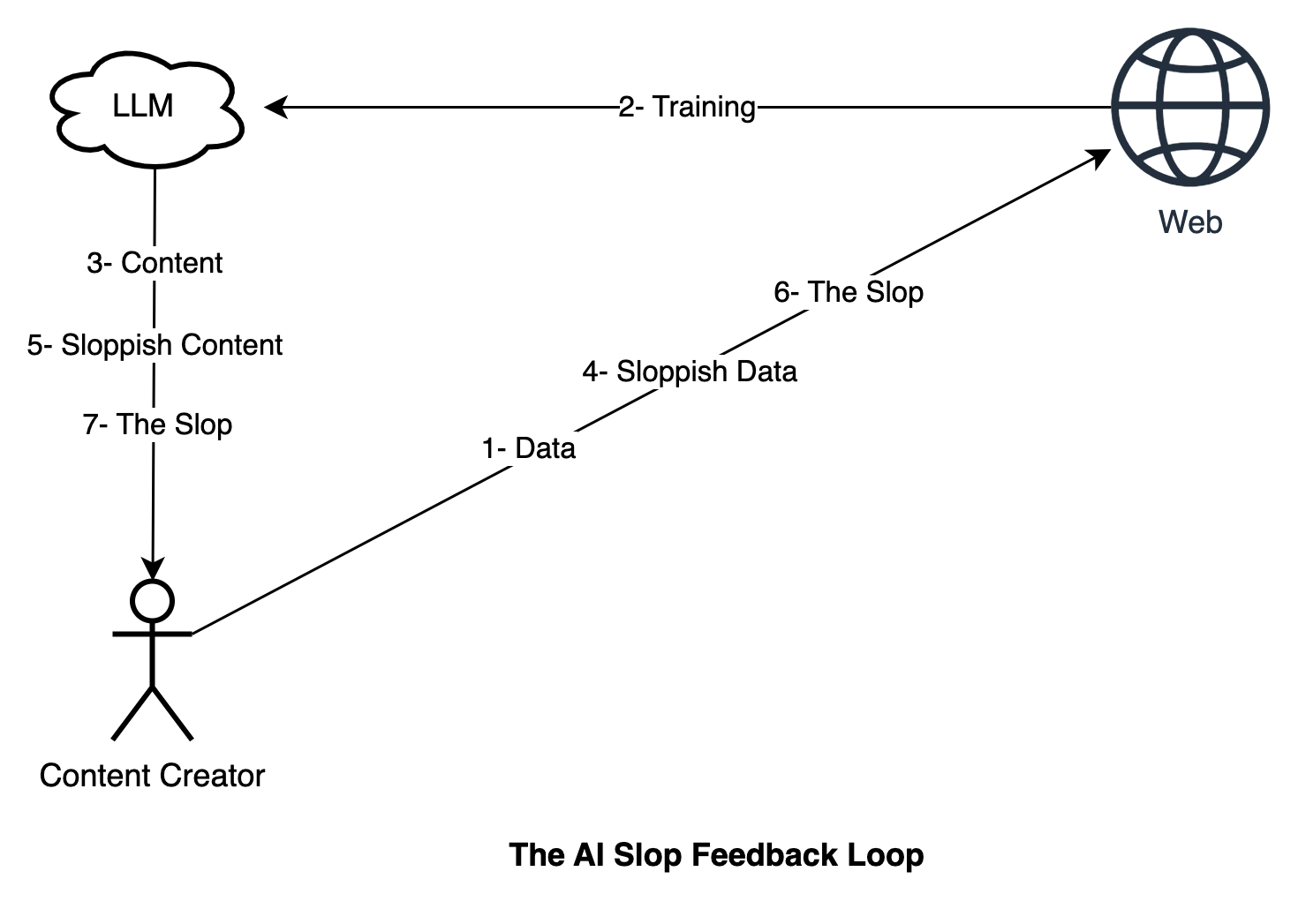
Once the previous knowledge ecosystem is broken, how will the LLM tools keep up? They simply can’t. They only generate based on what they have been trained on, and once new, factual, human-verified, creative, and helpful data is no longer available for training, they cannot give out useful content. Without human input, AI stagnates, and with AI-assisted minimal human input, the AI slop feedback loop happens. I believe if the knowledge ecosystem is not redeemed, and the new models are fed on their own generated slop, the quality of content will deteriorate quickly to the point where you wouldn’t be able to use the AI tools for anything new because there won’t be much available past the documentation of the technology. More compute and parameters won’t help.
The Solution and Predictions
The solution is to achieve the right equilibrium between AI and human contribution. We cannot shut one down completely in favor of the other. The sooner we balance it, the better.
Below are my low-key predictions about the coming times, which also serve as possible solutions:
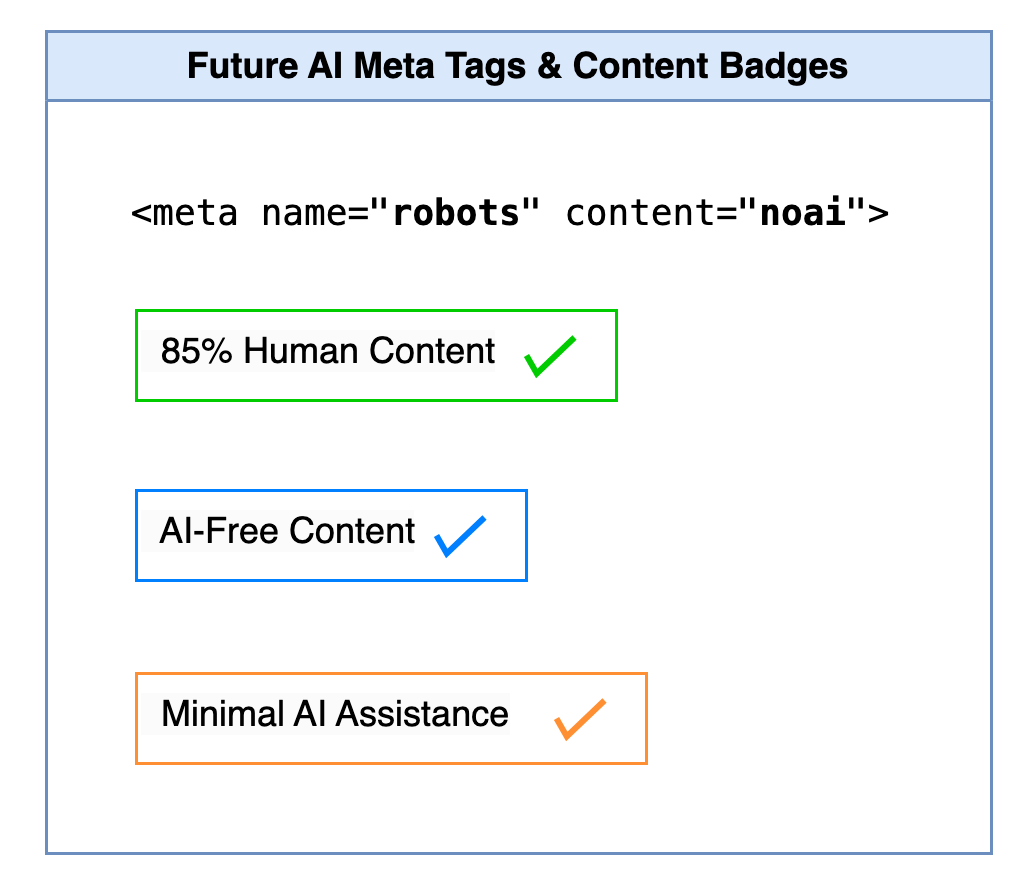
Once the AI hallucinations for newer technologies and frameworks become evident, I believe there will come closed, gated developer communities. Paid books and courses will become a norm, with legal guarantees to authors and creators of not selling their content for AI training. Micropayments for verified knowledge might be adopted at a large scale. Some platforms may someday need to assure their consumers that they are “AI-free” (much like GDPR compliance). Similar to “noindex”, new meta tags, such as “noai”, will be introduced to add to your content for AI robots to respect and not scrap (not enforceable, of course). Solutions will offer protection against AI training of your public content in addition to DDoS attacks. Automated services will audit your websites and provide you a badge of human vs AI content percentage, where securing an 80%+ human rating would be a huge achievement and trust factor for readers. Essentially, an arms race will start between AI detection and AI evasion tools, both playing the catch-up game. And, most probably, some incentive will have to be introduced for the publishers, content writers, and contributors, for them to continue adding helpful content in exchange for money.
The pendulum will surely swing the other way, making a non-AI or low-AI a badge of honor for individuals and companies alike.