
Airtable is a tool much like Google sheets, only way more advanced; it is a low-code platform for building collaborative applications.
You might be interested in consuming Airtable data in your applications, especially MVPs or POCs. For that, you can build APIs that return data sourced from Airtable. In this post, I share multiple ways you can achieve this, along with their pros and cons. I only discuss the reading Airtable part, not adding, updating, or deleting the records (only R from CRUD). So the question I answer is that given the Airtable as a source of data truth, how best can we serve this data to the end user in an application?
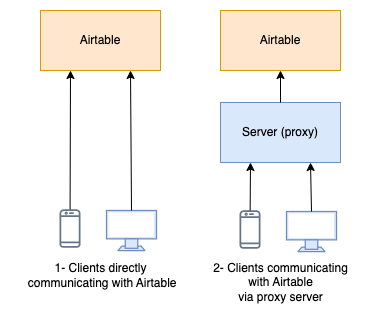
1- Direct Communication With Airtable Web APIs
The most obvious and easy way to consume Airtable data is using their own Web APIs. The official docs for API integration mention the available SDKs, including, as of now, JavaScript, Ruby, Python, and . Net. In addition, the docs document HTTP API calls for direct use where SDK is unavailable in a particular programming language.
You will need an Airtable API key to start fetching Airtable tables data directly on your backend or frontend application using one of the SDKs or direct HTTP API calls.
Note that if frontend is the place you need to use the Airtable data, adding a server will act as a proxy between the frontend and Airtable.
Pros
- It doesn’t need a separate infrastructure, including a server and database.
- You can filter the records by formula or view directly through the API parameters without doing anything on the client side.
Cons
- Complete reliance on Airtable for their APIs to work flawlessly at all times. You can’t do anything if/when Airtable Web APIs go down.
- You don’t have control over improving API response latency. You solely rely on Airtable services, which may not be to your satisfaction.
- Airtable puts a limit of 5 requests per second on the consumption of their Web APIs . It’s the limit they don’t change on any pricing tier. So as soon as your application API consumption goes beyond 5 requests per second, your requests will be throttled. This is the biggest and limiting drawback of Airtable APIs.
- Adding a server as a proxy introduces additional latency.
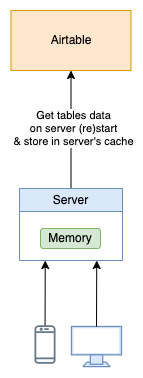
2- Server Without Database & Cache-Store
A relatively low-cost option is to have a server (or servers) that loads all the to-be-consumed data from Airtable on server start and then serves the incoming requests with the in-memory cached data.
Since the server(s) are not supposed to restart or frequently restart, you will have to build some re-sync logic to keep the in-memory cached data up-to-date with the Airtable changes.
Pros
- No continuous reliance on Airtable APIs. The APIs are called only once at the server start.
- Airtable data is easily stored on the server in JSON arrays of objects, where a table on Airtable corresponds to a JSON array, and each row is an object of the array, with fields as keys and values as values.
- The control to optimize/improve your APIs response time is independent of Airtable Web APIs. The complete infrastructure is in your possession, and you can enhance the API performance.
Cons
- For big data in the tables of Airtables, multiple pagination calls will be required at the beginning of the server start to collect the complete data.
- For more than one server, the number of initial API calls for data collection will be = (the number of servers * initial API calls).
- To fetch filtered records or to get one record by id, the whole in-memory data will need to be scanned, resulting in slow queries and API response times (unless you generate a query-based key-value hash at the start of the server once complete data is available after the pagination calls).
- Duplication of the same in-memory data for more than one server.
- Considerably big Airtable data will overwhelm the server(s) RAM.
- The requirement of re-sync logic to keep the server in-memory cached data updated.
3- Server With a Cache-Store
With a cache store, such as Redis, the responsibility of loading data on server start or restart is no more. Now, you can fill up the Redis store with a non-user-facing separate script, and the only responsibility of the server is to serve the content from this store.
Note that you’ll have to rethink how you will cache and fetch the data with a key-value cache store like Redis. For instance, to store all the records of a table “users” on Airtable, you might prepend the key of the record in Redis with “user”, such as, “user_1”, “user_2”, “user_99,” and store the whole JSON record as value. Now to get all users, you need to provide a pattern to Redis to fetch all keys and their values starting with “users_”.
Pros
- Separation of concerns and responsibilities between the cache store and server: The cache stores the in-memory data, and the server serves it.
- The number of servers no longer determines the initial API calls required to load the Airtable data. One Redis instance requires only one set of API calls (no duplication) to Airtable on each data sync operation.
- Getting record by id will take a constant lookup time out of the box.
Cons
- We need to reconsider how to map and store Airtable data in the cache store.
- The filtered data still requires O(N) time lookup because of scanning all fields that fulfill the pattern.
- The requirement of re-sync logic to update the cache store frequently.

4- Server With a Persistent Storage
The least cost-effective but the most flexible option is to introduce a database into the equation. All the Airtable data goes to the database, where retrieval is easy and quick.
Its most significant benefit is the ease of use and flexibility, with proper database schema and indexing in place for faster and easier data retrieval. Its drawback is the additional infrastructure cost plus the need to maintain schema for Airtable to database mapping.
Unlike the previous methods, where the server or a script takes action to retrieve the Airtable data, using the database as a persistent storage layer, we now have two options to load/sync data to the database, both with their own pros and cons.
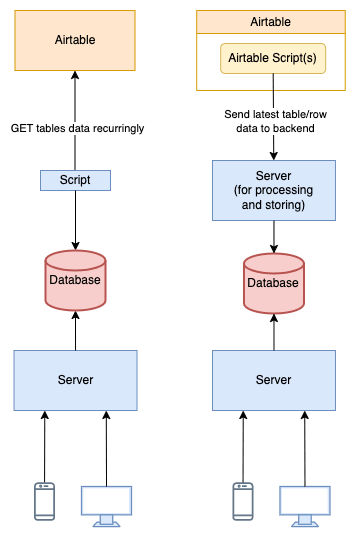
i) Use Sync Script to Add and Update the Database
The first method is the same regarding the direction of the data flow and who initiates the process. The dedicated script starts the sync process, calling the Airtable APIs to fetch the data, processing it, and storing it in the database.
Pros
- Sync data is handled in bulk. We take the whole table data from the Airtable and update the database table or collection. It’s essentially emptying the table and refilling it with all the records.
Cons
- The pro mentioned above is also a con. We must add, update, or delete all the records during the sync process, as we take the whole Airtable data in bulk. The best we can do is restrict the data to be processed based on the timestamp on the Airtable table.
ii) Use Airtable Scripts to Send Data to Your Server and Update the Database
The control is inverted. You write a script on Airtable that sends the data of the whole table or one record to your server on the API you’ve exposed for this purpose. You receive the payload and update the database with the latest record/table data.
Pros
- The responsibility of the server is reduced. It will be informed by the Airtable when to update the data on its end. It could be several times a day or once a month; the server doesn’t need to care.
Cons
- In addition to the server and database, you must keep scripts and their logic on Airtable.
- You rely on the data-entry person using Airtable to update the backend database whenever things are ready. Forgetting that will mean stale data on the database.
- In the case of bulk table sync, the same drawbacks are there as in the first case.
- You need to secure Airtable from unwanted access. A person with the access to your Airtable can intentionally or unintentionally corrupt Airtable and database data.
- You also need to ensure that the API for data sync only entertains calls made by the Airtable script, or else anyone could overwhelm the API or corrupt the data.
Conclusion: Who’s the Winner?
Depending on your requirement, the above methods offer options from quick and cost-effective to slow and expensive. Remember that quick and slow here mean the development and validation time rather than the efficiency or flexibility of your solution. Fast implementation is best for validating things but is inefficient in the long run. These are the tradeoffs you need to discuss before choosing any option.
The long-term and the most flexible solution of the lot is the one with a full-fledged database. However, setting up the infrastructure does take time, not to mention the time it needs to reach confident decisions such as the selection of SQL or NoSql database, plus the flavor of it.
The middle ground is the introduction of a cache store like Redis. The data is more loosely stored in this case than in any schema-based database. But it’s still better than relying on the backend servers to keep in-memory data, which is more volatile and coupled.
The most cost-effective solution is using the Airtable existing APIs directly. However, the limiting factors are over-reliance on the services of Airtable and keeping the calls under their 5 requests per second rate-limiting, irrespecitive of your price tier.